# load packages
library(tidyverse) # for data wrangling
library(tidymodels) # for modeling
library(fivethirtyeight) # for the fandango dataset
library(knitr) # for formatting tables
# set default theme and larger font size for ggplot2
ggplot2::theme_set(ggplot2::theme_bw(base_size = 16))
# set default figure parameters for knitr
knitr::opts_chunk$set(
fig.width = 8,
fig.asp = 0.618,
fig.retina = 3,
dpi = 300,
out.width = "80%"
)Simple Linear Regression
Announcements
- No labs or office hours Monday, January 20 - Martin Luther King Jr. Holiday
- Introduction to R workshops at Duke library
- Data wrangling with dplyr - Thu, Jan 16 at 12pm
- Data visualization with ggplot2 - Thu, Jan 23 at 12pm
Topics
Use simple linear regression to describe the relationship between a quantitative predictor and quantitative response variable.
Estimate the slope and intercept of the regression line using the least squares method.
Interpret the slope and intercept of the regression line.
Predict the response given a value of the predictor variable.
Fit linear regression models in R
Computation set up
Data
Movie scores
- Data behind the FiveThirtyEight story Be Suspicious Of Online Movie Ratings, Especially Fandango’s
- In the fivethirtyeight package:
fandango - Contains every film released in 2014 and 2015 that has at least 30 fan reviews on Fandango, an IMDb score, Rotten Tomatoes critic and user ratings, and Metacritic critic and user scores




Data prep
- Rename Rotten Tomatoes columns as
criticsandaudience - Rename the data set as
movie_scores
movie_scores <- fandango |>
rename(critics = rottentomatoes,
audience = rottentomatoes_user)Data overview
glimpse(movie_scores)Rows: 146
Columns: 23
$ film <chr> "Avengers: Age of Ultron", "Cinderella", "A…
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2…
$ critics <int> 74, 85, 80, 18, 14, 63, 42, 86, 99, 89, 84,…
$ audience <int> 86, 80, 90, 84, 28, 62, 53, 64, 82, 87, 77,…
$ metacritic <int> 66, 67, 64, 22, 29, 50, 53, 81, 81, 80, 71,…
$ metacritic_user <dbl> 7.1, 7.5, 8.1, 4.7, 3.4, 6.8, 7.6, 6.8, 8.8…
$ imdb <dbl> 7.8, 7.1, 7.8, 5.4, 5.1, 7.2, 6.9, 6.5, 7.4…
$ fandango_stars <dbl> 5.0, 5.0, 5.0, 5.0, 3.5, 4.5, 4.0, 4.0, 4.5…
$ fandango_ratingvalue <dbl> 4.5, 4.5, 4.5, 4.5, 3.0, 4.0, 3.5, 3.5, 4.0…
$ rt_norm <dbl> 3.70, 4.25, 4.00, 0.90, 0.70, 3.15, 2.10, 4…
$ rt_user_norm <dbl> 4.30, 4.00, 4.50, 4.20, 1.40, 3.10, 2.65, 3…
$ metacritic_norm <dbl> 3.30, 3.35, 3.20, 1.10, 1.45, 2.50, 2.65, 4…
$ metacritic_user_nom <dbl> 3.55, 3.75, 4.05, 2.35, 1.70, 3.40, 3.80, 3…
$ imdb_norm <dbl> 3.90, 3.55, 3.90, 2.70, 2.55, 3.60, 3.45, 3…
$ rt_norm_round <dbl> 3.5, 4.5, 4.0, 1.0, 0.5, 3.0, 2.0, 4.5, 5.0…
$ rt_user_norm_round <dbl> 4.5, 4.0, 4.5, 4.0, 1.5, 3.0, 2.5, 3.0, 4.0…
$ metacritic_norm_round <dbl> 3.5, 3.5, 3.0, 1.0, 1.5, 2.5, 2.5, 4.0, 4.0…
$ metacritic_user_norm_round <dbl> 3.5, 4.0, 4.0, 2.5, 1.5, 3.5, 4.0, 3.5, 4.5…
$ imdb_norm_round <dbl> 4.0, 3.5, 4.0, 2.5, 2.5, 3.5, 3.5, 3.5, 3.5…
$ metacritic_user_vote_count <int> 1330, 249, 627, 31, 88, 34, 17, 124, 62, 54…
$ imdb_user_vote_count <int> 271107, 65709, 103660, 3136, 19560, 39373, …
$ fandango_votes <int> 14846, 12640, 12055, 1793, 1021, 397, 252, …
$ fandango_difference <dbl> 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5…Movie scores data
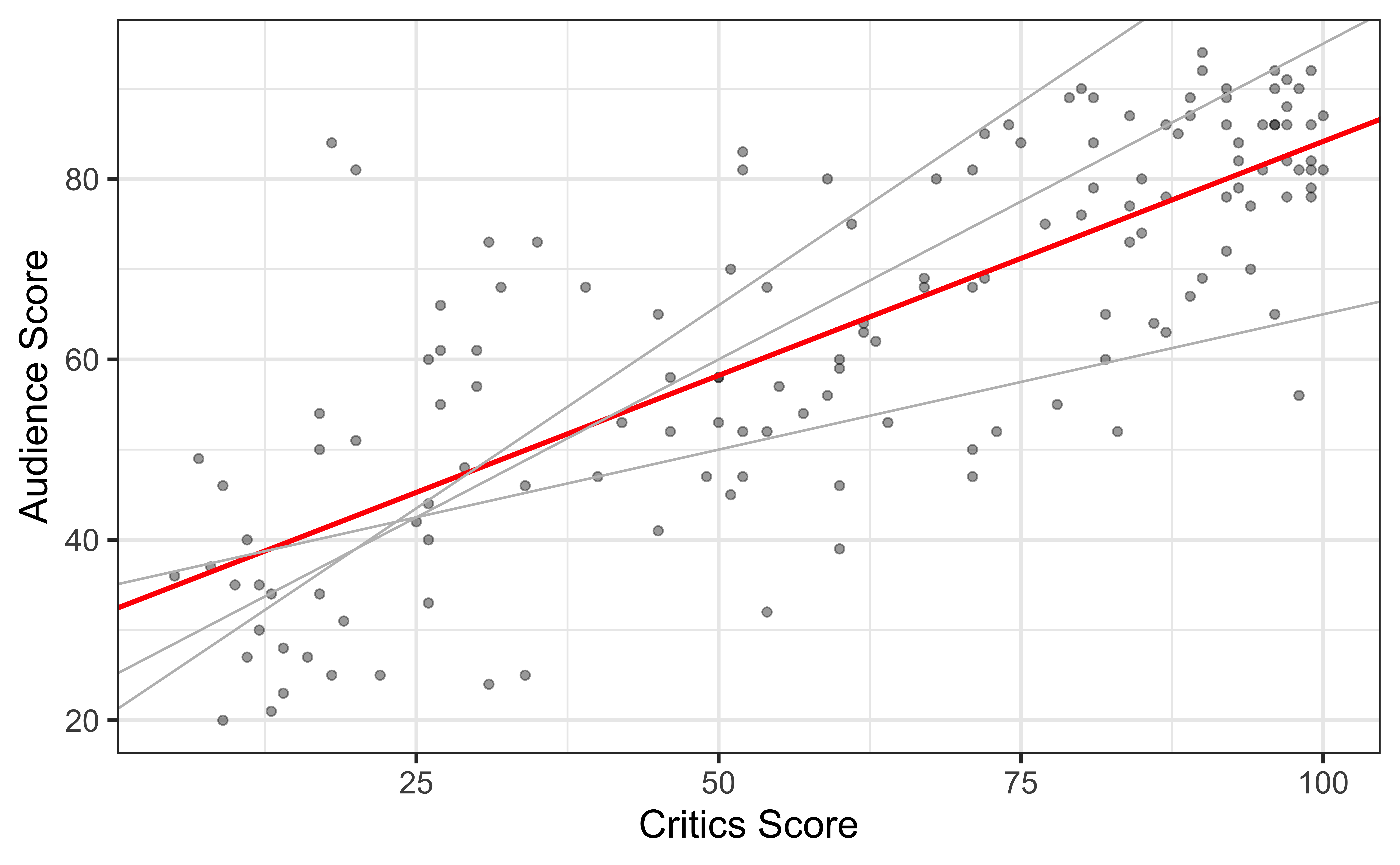
The data set contains the “Tomatometer” score (critics) and audience score (audience) for 146 movies rated on rottentomatoes.com.
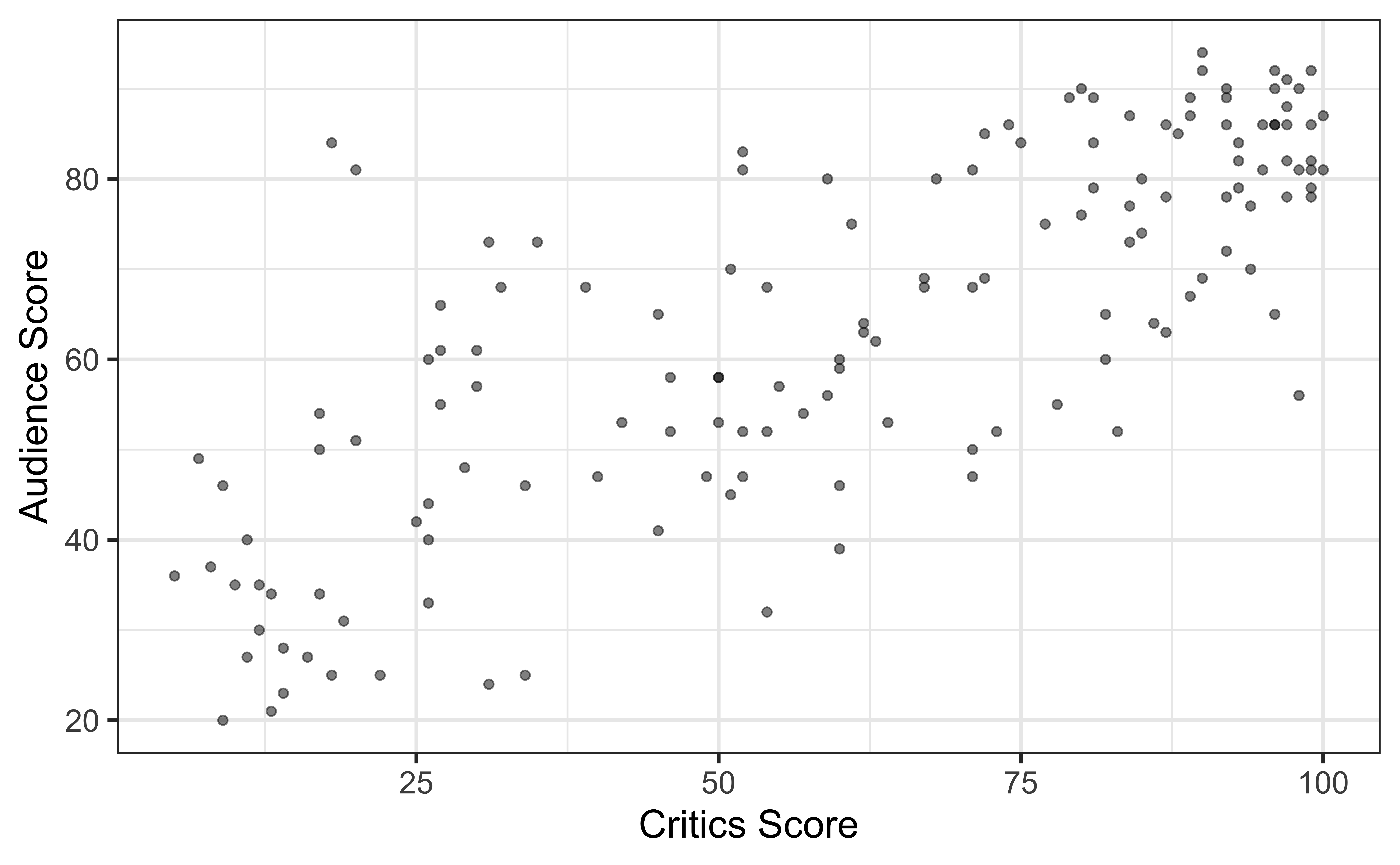
Movie ratings data
Goal: Fit a line to describe the relationship between the critics score and audience score.
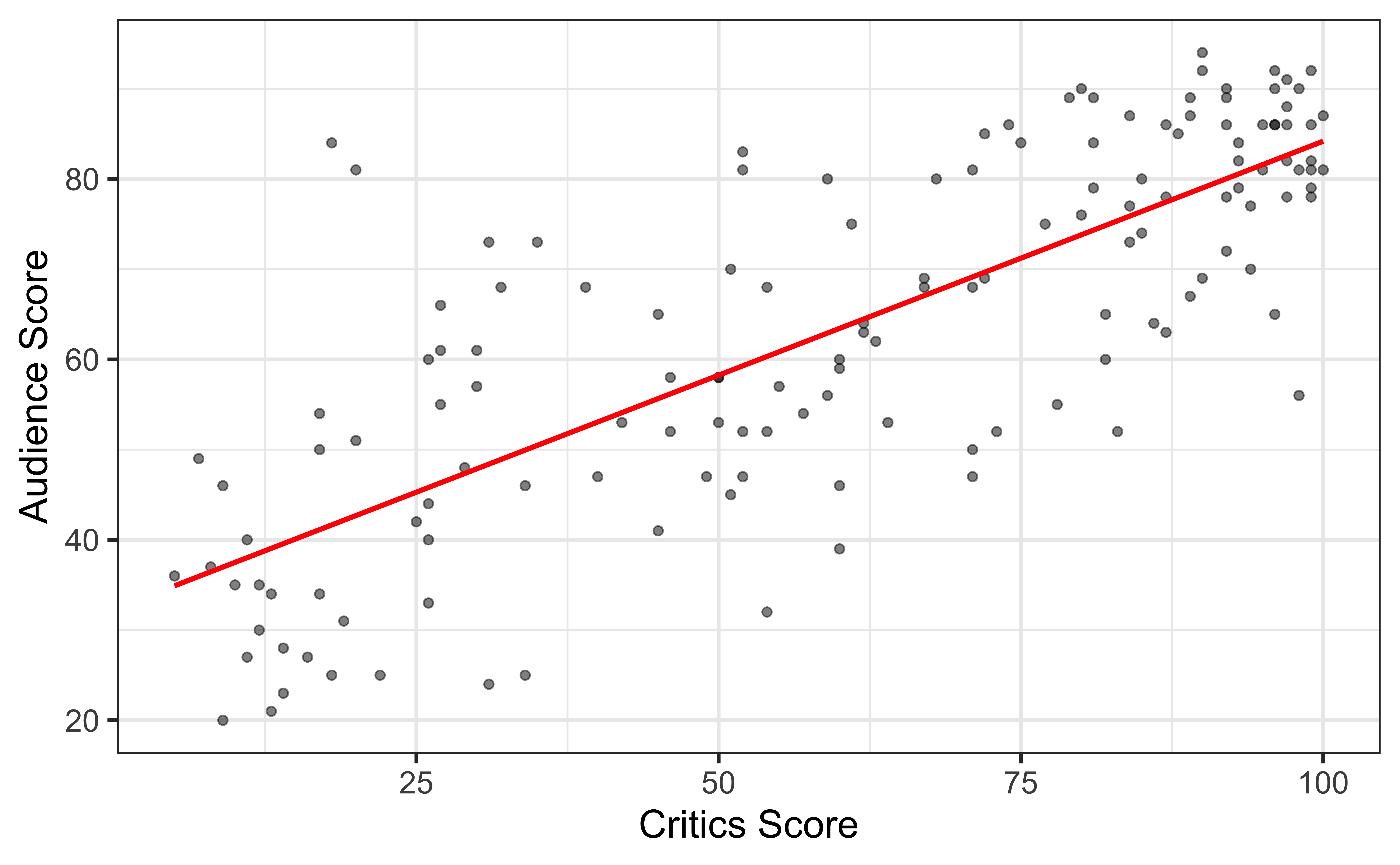
Why fit a line?
We fit a line to accomplish one or both of the following:
. . .
Prediction
What is the audience score expected to be for an upcoming movie that received 35% from the critics?
. . .
Inference
Is the critics score a useful predictor of the audience score? By how much is the audience score expected to change for each additional point in the critics score?
Terminology
Response, Y: variable describing the outcome of interest
Predictor, X: variable we use to help understand the variability in the response
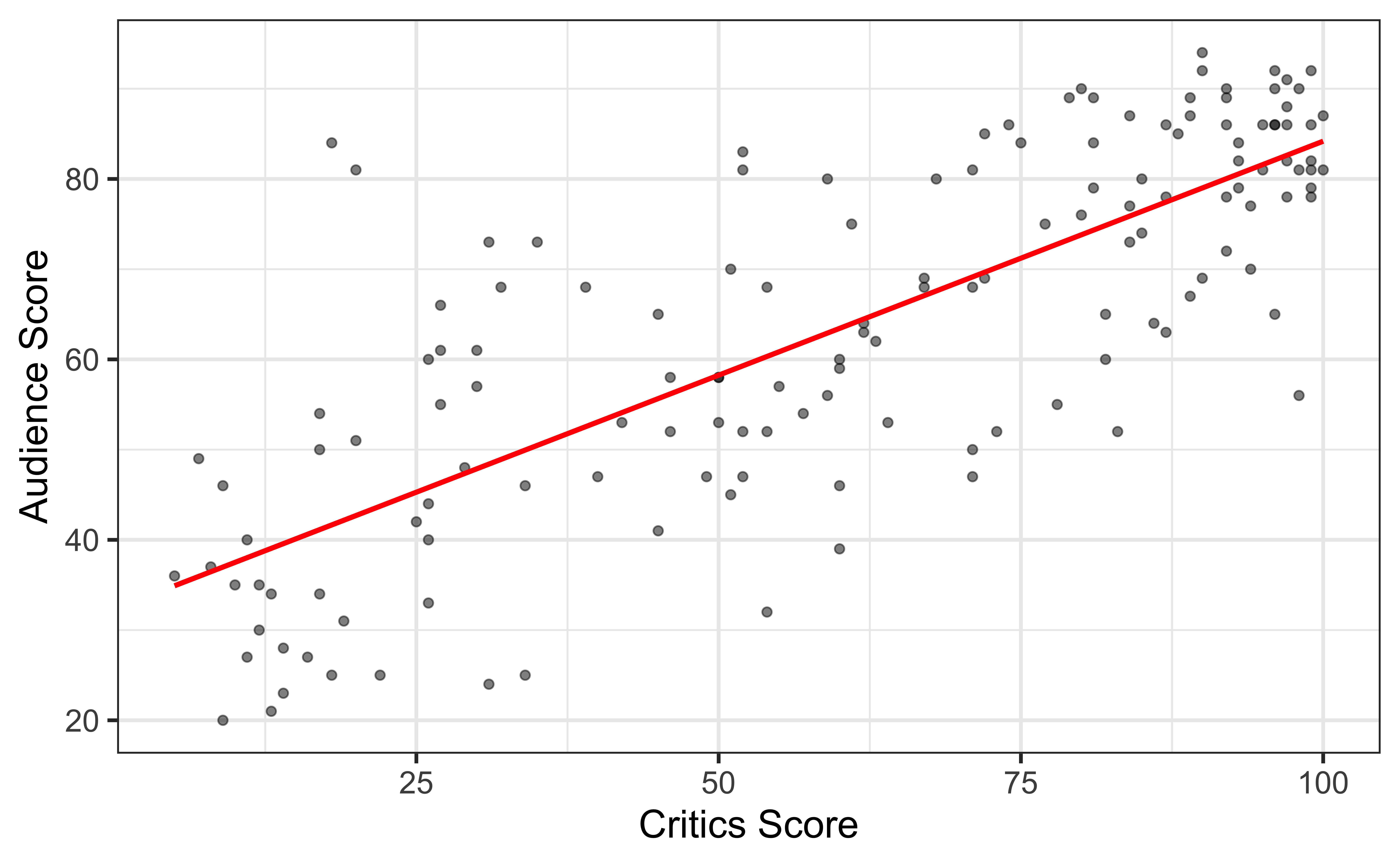
Regression model
A regression model is a function that describes the relationship between the response, \(Y\), and the predictor, \(X\).
\[\begin{aligned} Y &= \color{black}{\textbf{Model}} + \text{Error} \\[8pt] &= \color{black}{\mathbf{f(X)}} + \epsilon \\[8pt] &= \color{black}{\mathbf{E(Y|X)}} + \epsilon \\[8pt] &= \color{black}{\boldsymbol{\mu_{Y|X}}} + \epsilon \end{aligned}\]Regression model
\[\begin{aligned} Y &= {\color{purple} \textbf{Model}} + \text{Error} \\[8pt]
&= {\color{purple} \mathbf{f(X)}} + \epsilon \\[8pt]
&= {\color{purple} \mathbf{E(Y|X)}} + \epsilon \\[8pt]
&= {\color{purple} \boldsymbol{\mu_{Y|X}}} + \epsilon \end{aligned}\]
\(\mu_{Y|X}\) is the mean value of \(Y\) given a particular value of \(X\).
Regression model
\[ \begin{aligned} Y &= \color{purple}{\textbf{Model}} + \color{blue}{\textbf{Error}} \\[8pt] &= \color{purple}{\mathbf{f(X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] &= \color{purple}{\mathbf{E(Y|X)}} + \color{blue}{\boldsymbol{\epsilon}} \\[8pt] &= \color{purple}{\boldsymbol{\mu_{Y|X}}} + \color{blue}{\boldsymbol{\epsilon}} \\[5pt] \end{aligned} \]
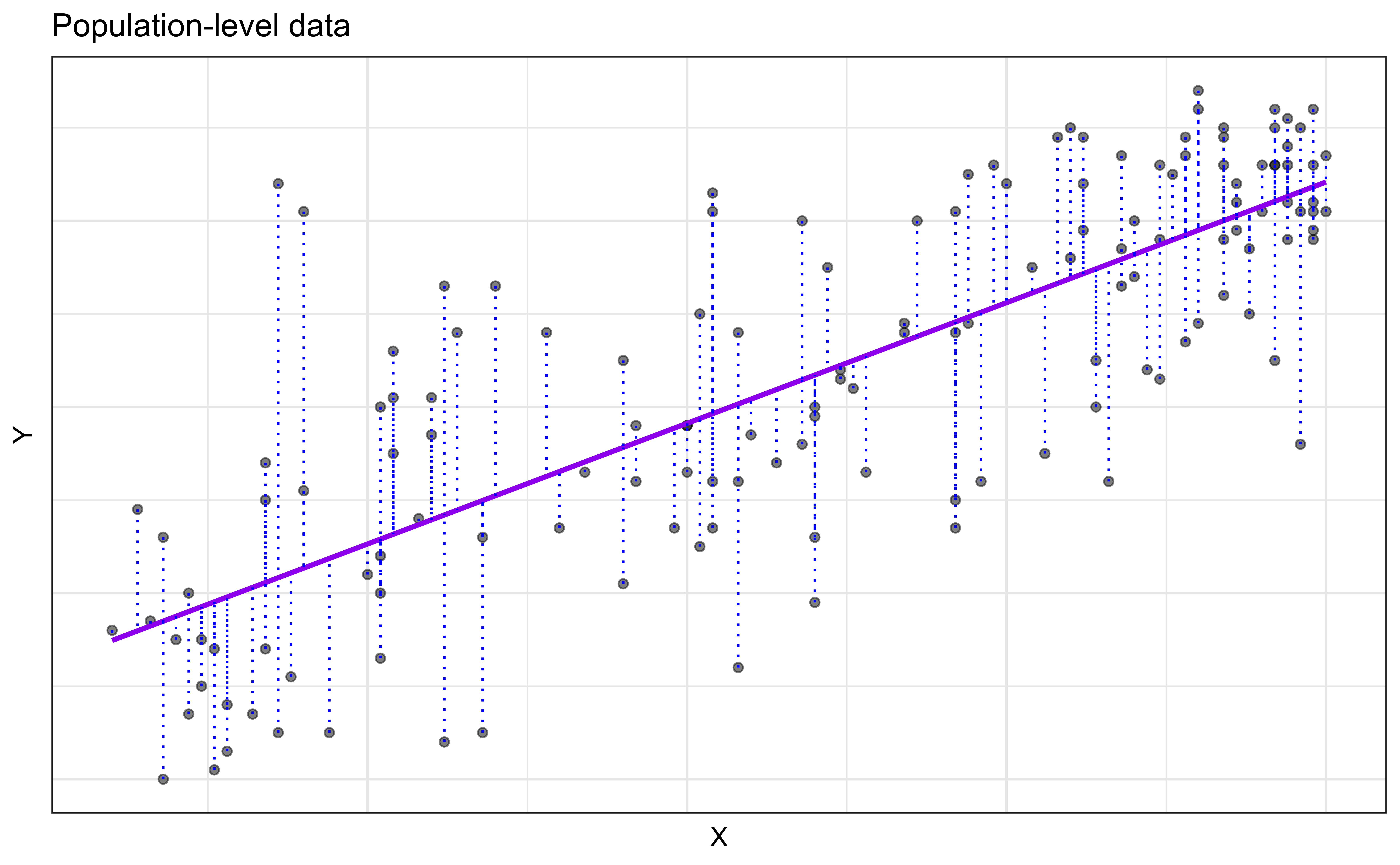
Simple linear regression (SLR)
SLR: Statistical model (Theoretical)
When we have a quantitative response, \(Y\), and a single quantitative predictor, \(X\), we can use a simple linear regression model to describe the relationship between \(Y\) and \(X\).
\[y_i = \beta_0 + \beta_1 x_i + \epsilon_i\]
. . .
- \(\beta_1\): True slope of the relationship between \(X\) and \(Y\)
- \(\beta_0\): True intercept of the relationship between \(X\) and \(Y\)
- \(\epsilon_i\): Error for the \(i^{th}\) observation
SLR: Regression equation (Fitted)
\[ \hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i \]
- \(\hat{\beta}_1\): Estimated slope of the relationship between \(X\) and \(Y\)
- \(\hat{\beta}_0\): Estimated intercept of the relationship between \(X\) and \(Y\)
- No error term!
. . .
Why is there no error term in the estimated regression equation?
Computing estimates \(\hat{\beta}_1\) and \(\hat{\beta}_0\)
Residuals
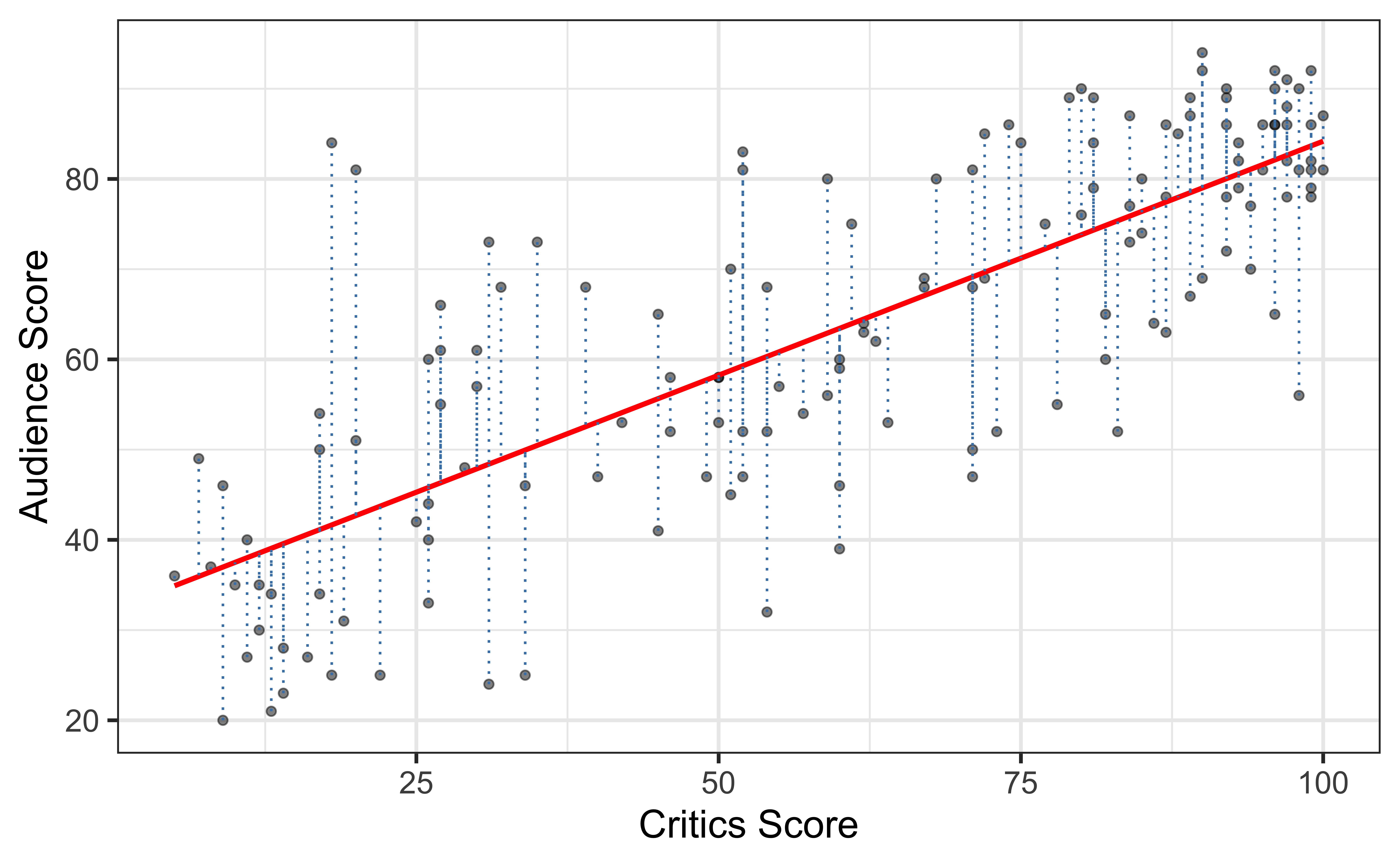
\[\text{residual} = \text{observed} - \text{predicted} = y_i - \hat{y}_i\]
Least squares line
- The residual for the \(i^{th}\) observation is
\[e_i = \text{observed} - \text{predicted} = y_i - \hat{y}_i\]
- The sum of squared residuals is
\[e^2_1 + e^2_2 + \dots + e^2_n\]
- The Ordinary Least Squares (OLS) line is the one that minimizes the sum of squared residuals
Steps to compute estimate \(\hat{\beta}_0\)
Click here for full details on estimating \(\hat{\beta}_0\) and \(\hat{\beta}_1\) for simple linear regression.
Slope and intercept
Properties of least squares regression
The regression line goes through the center of mass point, the coordinates corresponding to average \(X\) and average \(Y\): \(\hat{\beta}_0 = \bar{y} - \hat{\beta}_1\bar{x}\)
The slope has the same sign as the correlation coefficient: \(\hat{\beta}_1 = r \frac{s_Y}{s_X}\)
The sum of the residuals is approximately zero: \(\sum_{i = 1}^n e_i \approx 0\)
The residuals and \(X\) values are uncorrelated
Estimating the slope
\[\large{\hat{\beta}_1 = r \frac{s_Y}{s_X}}\]
\[\begin{aligned}
s_X &= 30.1688 \\
s_Y &= 20.0244 \\
r &= 0.7814
\end{aligned}\]
\[\begin{aligned}
\hat{\beta}_1 &= 0.7814 \times \frac{20.0244}{30.1688} \\
&= 0.5187\end{aligned}\]
Estimating the intercept
\[\large{\hat{\beta}_0 = \bar{Y} - \hat{\beta}_1\bar{X}}\]
\[\begin{aligned}
&\bar{x} = 60.8493 \\
&\bar{y} = 63.8767 \\
&\hat{\beta}_1 = 0.5187
\end{aligned}\]
\[\begin{aligned}\hat{\beta}_0 &= 63.8767 - 0.5187 \times 60.8493 \\
&= 32.3142
\end{aligned}\]
Interpretation
\[ \widehat{\text{audience}} = 32.3142 + 0.5187 \times \text{critics} \]
Answer the following questions on Ed Discussion:
The slope of the model for predicting audience score from critics score is 0.5187 . Which of the following is the best interpretation of this value?
32.3142 is the predicted mean audience score for what type of movies?
Does it make sense to interpret the intercept?
. . .
✅ The intercept is meaningful in the context of the data if
the predictor can feasibly take values equal to or near zero, or
there are values near zero in the observed data.
. . .
🛑 Otherwise, the intercept may not be meaningful!
Prediction
Making a prediction
Suppose that a movie has a critics score of 70. According to this model, what is the movie’s predicted audience score?
\[\begin{aligned} \widehat{\text{audience}} &= 32.3142 + 0.5187 \times \text{critics} \\ &= 32.3142 + 0.5187 \times 70 \\ &= 68.6232 \end{aligned}\]. . .
Caution
Using the model to predict for values outside the range of the original data is extrapolation. Why do we want to avoid extrapolation?
Linear regression in R
Fit the model
Use the lm() function to fit a linear regression model
movie_fit <- lm(audience ~ critics, data = movie_scores)
movie_fit
Call:
lm(formula = audience ~ critics, data = movie_scores)
Coefficients:
(Intercept) critics
32.3155 0.5187 Tidy results
Use the tidy() function from the broom R package to “tidy” the model output
Format results
Use the kable() function from the knitr package to neatly format the results
Prediction
Use the predict() function to calculate predictions for new observations
Single observation
new_movie <- tibble(critics = 70)
predict(movie_fit, new_movie) 1
68.62297 Prediction
Use the predict() function to calculate predictions for new observations
Multiple observations
more_new_movies <- tibble(critics = c(24,70, 85))
predict(movie_fit, more_new_movies) 1 2 3
44.76379 68.62297 76.40313 Application exercise
Find your
ae-03repo in the course GitHub organization.If you do not see an
ae-03repo, use the link to create one: https://classroom.github.com/a/jxxCTVVo
Recap
Used simple linear regression to describe the relationship between a quantitative predictor and quantitative response variable.
Used the least squares method to estimate the slope and intercept.
Interpreted the slope and intercept.
Predicted the response given a value of the predictor variable.
Used R to fit the regression line and calculate predictions