library(tidyverse)
library(tidymodels)
library(knitr)
library(nnet)
# Include other packages as neededLab 06: Multinomial logistic regression
Due date
This lab is due on Tuesday, April 15 11:59pm. To be considered on time, the following must be done by the due date:
- Final
.qmdand.pdffiles pushed to your team’s GitHub repo - Final
.pdffile submitted on Gradescope
Multinomial logistic regression
In this lab, you will use multinomial logistic regression to understand how different conditions of a crime and suspect lineup impact individuals’ ability to correctly identify the perpetrator. You will also use cross validation to compare and evaluate candidate models. The data are from a mock crime scenario in a 2014 experiment.
Learning goals
By the end of the lab you will be able to…
interpret visualizations in the exploratory data analysis for multinomial logistic regression.
fit and interpret multinomial logistic regression model.
use cross validation to fit and compare models.
Packages
Fill in the packages you need to complete the assignment in your R Markdown document.
Data
For this assignment, we will analyze data from the eye witness identification experiment in Carlson and Carlson (2014). In this experiment, participants were asked to watch a video of a mock crime (from the first person perspective), spend a few minutes completing a random task, and then identify the perpetrator of the mock crime from a line up shown on the screen. Every lineup in this analysis included the true perpetrator from the video. After viewing the line-up , each participant was asked to make a decision. This decision is the response variable
id: Decision made by participant. It takes one of the following values:correct: correctly identified the true perpetratorfoil: incorrectly identified the “foil”, i.e. a person who looks very similar to the perpetratorreject: incorrectly concluded the true perpetrator is not in the lineup
The main objective of the analysis is to understand how different conditions of the mock crime and suspect lineup affect the decision made by the participant. We will consider the following conditions to describe the decisions. These are the predictor variables:
lineup: How potential suspects are shown to the participantsSimultaneous Lineup: Participants were shown photos of all 6 potential suspects at the same time and were required to make a single decision (identify someone from the lineup or reject the lineup).Sequential 5 Lineup: Photos of the 6 suspects were shown one at a time. The participant was required to make a decision (choose or don’t choose) as each photo was shown. Once a decision was made, participants were not allowed to reexamine a photo. If the participant made an identification, the remaining photos were not shown. In each of these lineups the true perpetrator was always the 5th photo in the lineup.
weapon: Whether or not a weapon was present in the video of the mock crime.feature: Whether or not the perpetrator had a distinctive marking on his face. In this experiment, the distinctive feature was a large “N” sticker on one cheek. (The letter “N” was chosen to represent the first author’s alma mater - University of Nebraska.)
The data may be found in eyewitness.csv in the data folder.
Exercises
Exercise 1
Let’s begin by doing the exploratory data analysis. Univariate and bivariate plots are shown below.
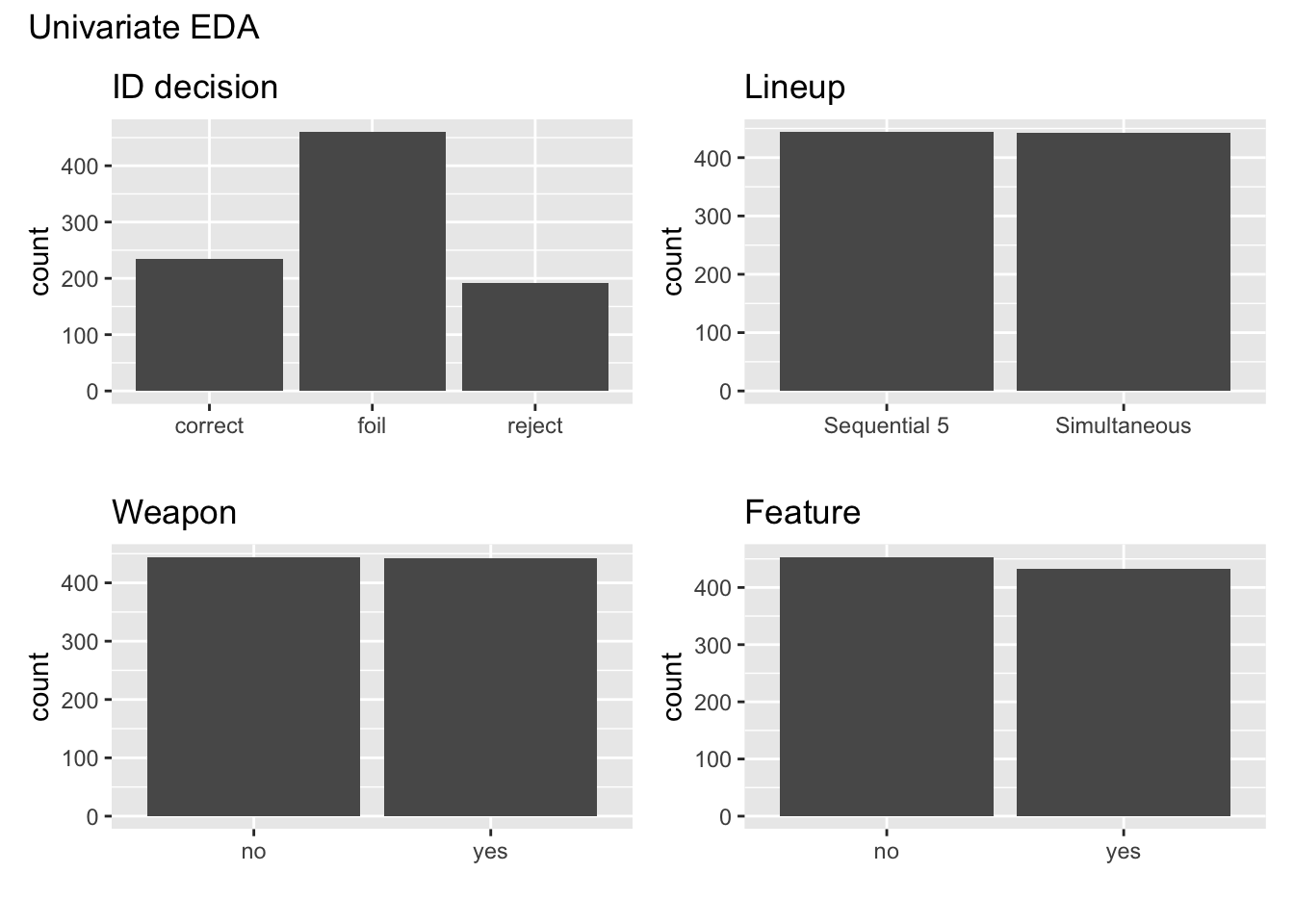
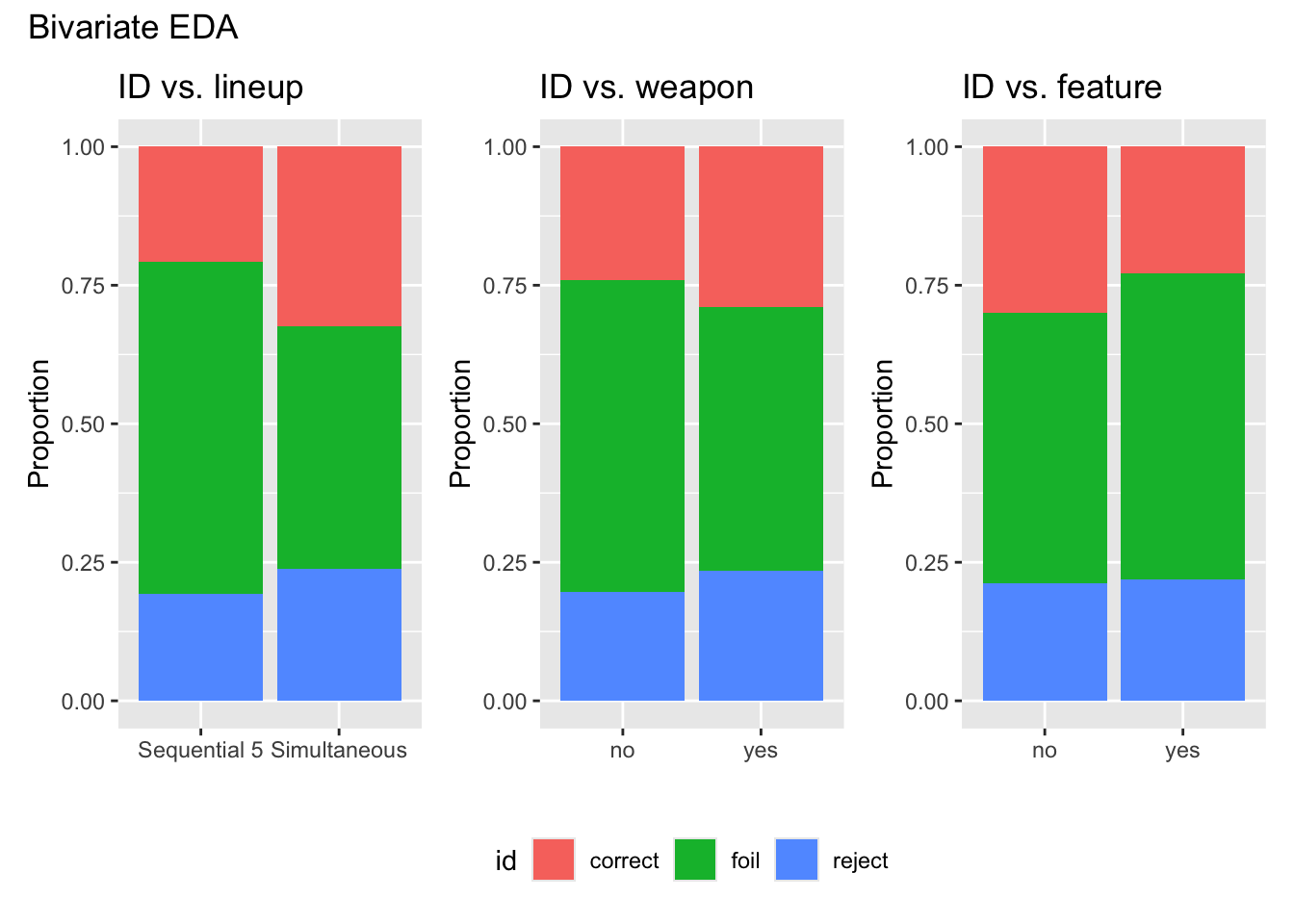
- Write two observations from the univariate EDA.
- Write two observations from the bivariate EDA.
Exercise 2
Make all the variables factor variable types. Then, split the data into training (75%) and test (25%) sets. Use seed 210.
How many observations are in the training set?
Exercise 3
- Briefly explain a multinomial logistic regression model is an appropriate model choice for predicting
idusinglineup,weaponandfeature. - Use the training data to fit a multinomial logistic model using only the main effects for
lineup,weapon, andfeature. Neatly display the model using 3 digits.
Exercise 4
- What is the baseline category for the response variable?
- What experimental conditions are described by the intercept?
- Interpret the coefficients of
lineupfor each part of the model in terms of the odds. - Use the coefficients and inferential statistics to describe the association between
lineupandid.
Exercise 5
You are considering a model that includes all possible interactions between the predictors lineup , weapon, and feature . You will use 5-fold cross validation to choose between the main effects model fit in Exercise 3 and the model with interaction effects.
Tip
See Cross Validation notes for relevant code.
- Use the training data and seed
210to create 5 folds. How many observations are in the assessment set for each fold? - Fit the main effects model on the 5 folds.
- What is the average accuracy across all folds? What is the average AUC?
Exercise 6
- Fit the interaction model on the 5 folds from the previous exercise.
- What is the average accuracy across all folds? What is the average AUC?
- Based on the cross validation results, do you choose the main effects model or the model with interactions? Briefly explain your response.
Exercise 7
If needed, fit the model selected in the previous exercise on the full training data.
Next, use the testing data to predict the classes of id, and make a confusion matrix of the actual versus predicted classes of id.
Lastly, use the confusion matrix to comment on the model performance.
Tip
Below is template code to compute predicted classes on a test set:
pred_class <- predict(model_name, test_set, type = "class")See Multinomial Logistic Regression: Inference + Prediction notes for additional help with code.
Submission
Submit your completed assignment as a PDF to Gradescope. Follow the instructions carefully to ensure your submission is complete.
Warning
Before you wrap up the assignment, make sure all documents are updated on your GitHub repo. We will be checking these to make sure you have been practicing how to commit and push changes.
Remember – you must turn in a PDF file to the Gradescope page before the submission deadline for full credit.
To submit your assignment:
Access Gradescope through the STA 210 Canvas site.
Click on the assignment, and you’ll be prompted to submit it.
Select all team members’ names, so they receive credit on the assignment. Click here for video on adding team members to assignment on Gradescope.
Mark the pages associated with each exercise. All of the pages of your lab should be associated with at least one question (i.e., should be “checked”).
Select the first page of your .PDF submission to be associated with the “Workflow & formatting” section.
Grading
| Component | Points |
|---|---|
| Exercise 1 | 4 |
| Exercise 2 | 4 |
| Exercise 3 | 4 |
| Exercise 4 | 10 |
| Exercise 5 | 8 |
| Exercise 6 | 6 |
| Exercise 7 | 9 |
| Workflow & formatting | 5 |
| Total | 50 |
The “Workflow & formatting” grade is to assess the reproducible workflow and collaboration. This includes having at least one meaningful commit from each team member, a neatly organized document with readable code, and updating the team name and date in the YAML.
References
Carlson, Curt A, and Maria A Carlson. 2014. “An Evaluation of Lineup Presentation, Weapon Presence, and a Distinctive Feature Using ROC Analysis.” Journal of Applied Research in Memory and Cognition 3 (2): 45–53. https://doi.org/https://doi.org/10.1016/j.jarmac.2014.03.004.