LR: Inference + conditions
Apr 03, 2025
Empirical logit plot in R (quantitative predictor)
Created using dplyr and ggplot functions.
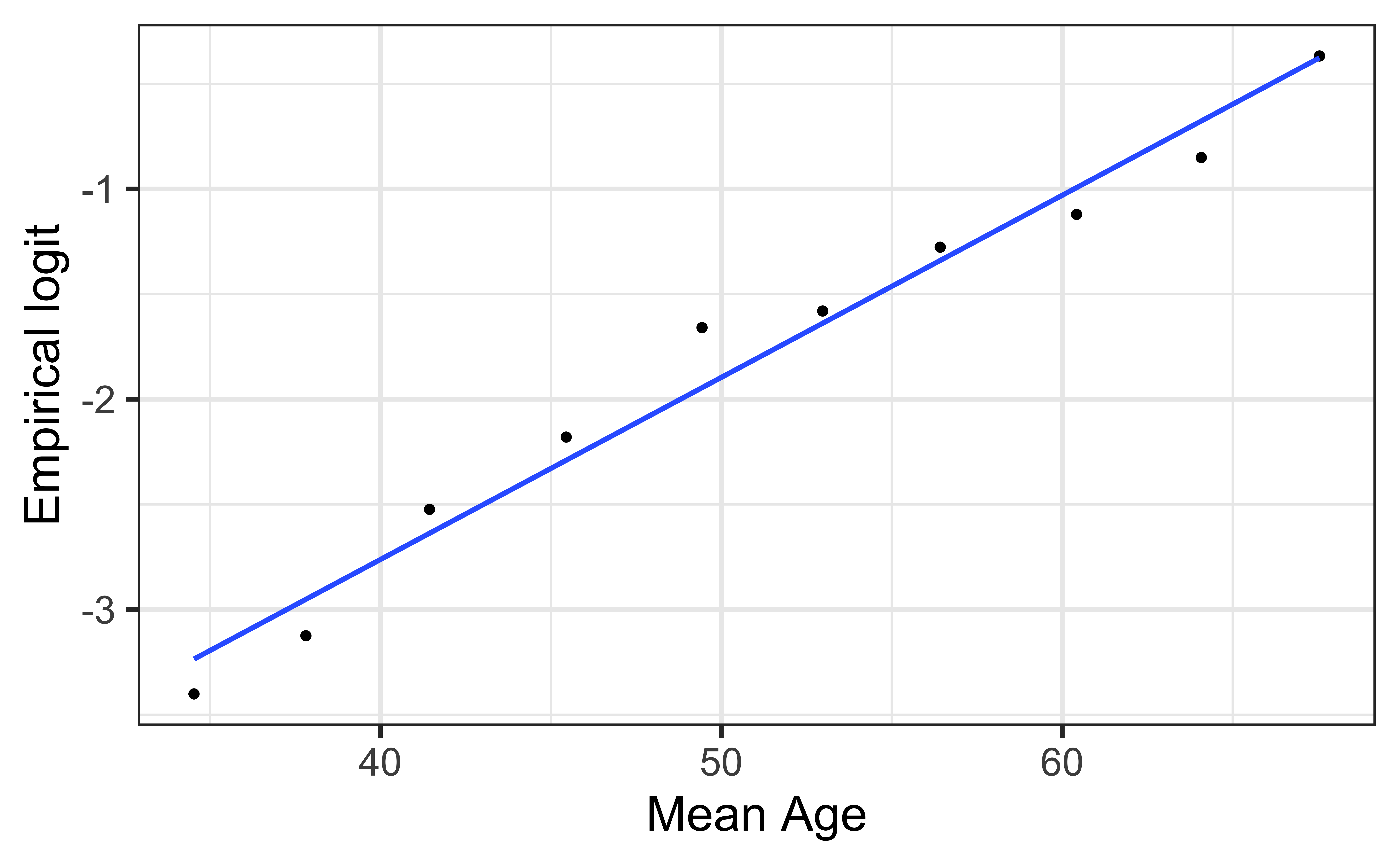
Empirical logit plot in R (quantitative predictor)
Using the emplogitplot1 function from the Stat2Data R package
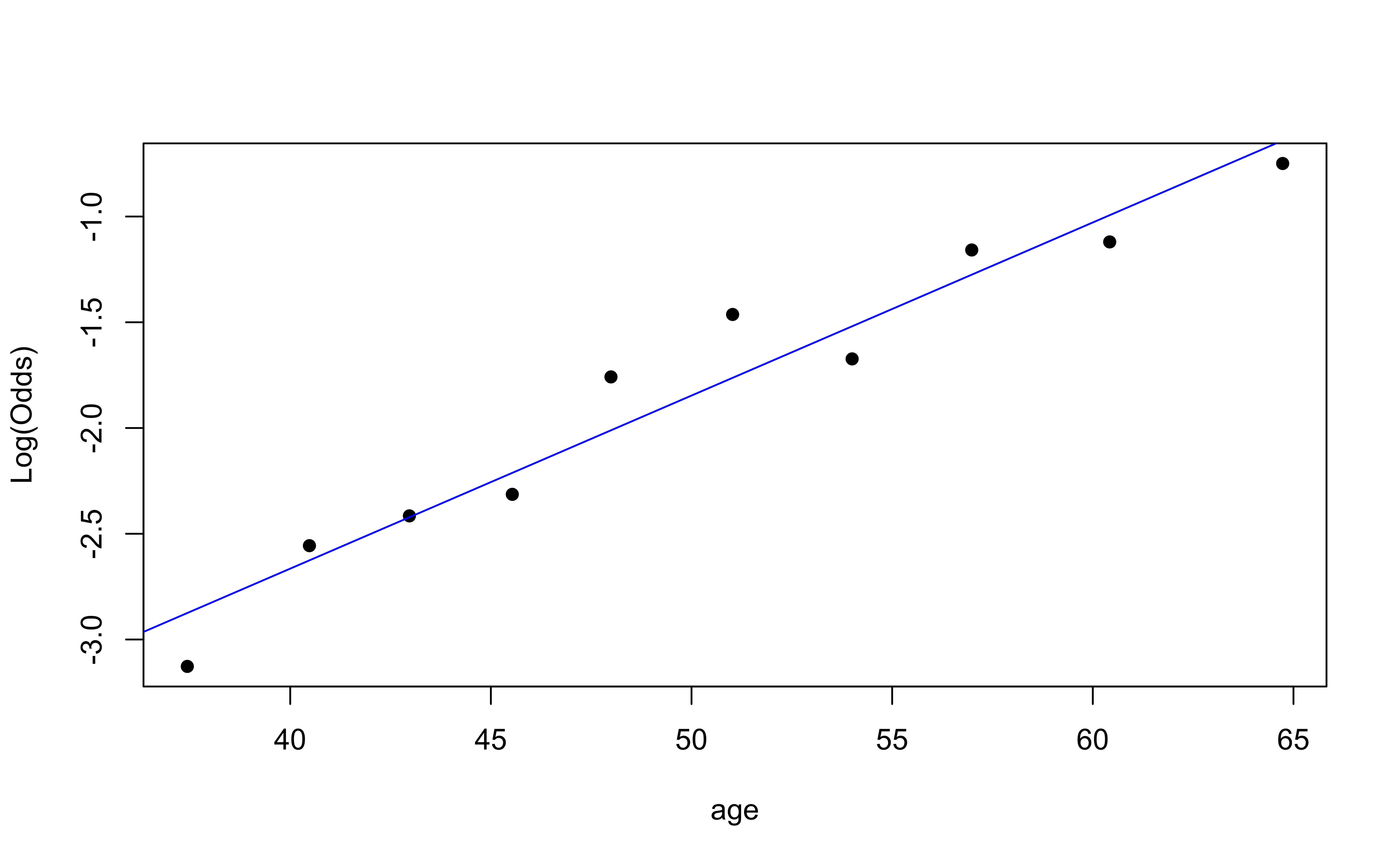
Empirical logit plot in R (interactions)
Using the emplogitplot2 function from the Stat2Data R package
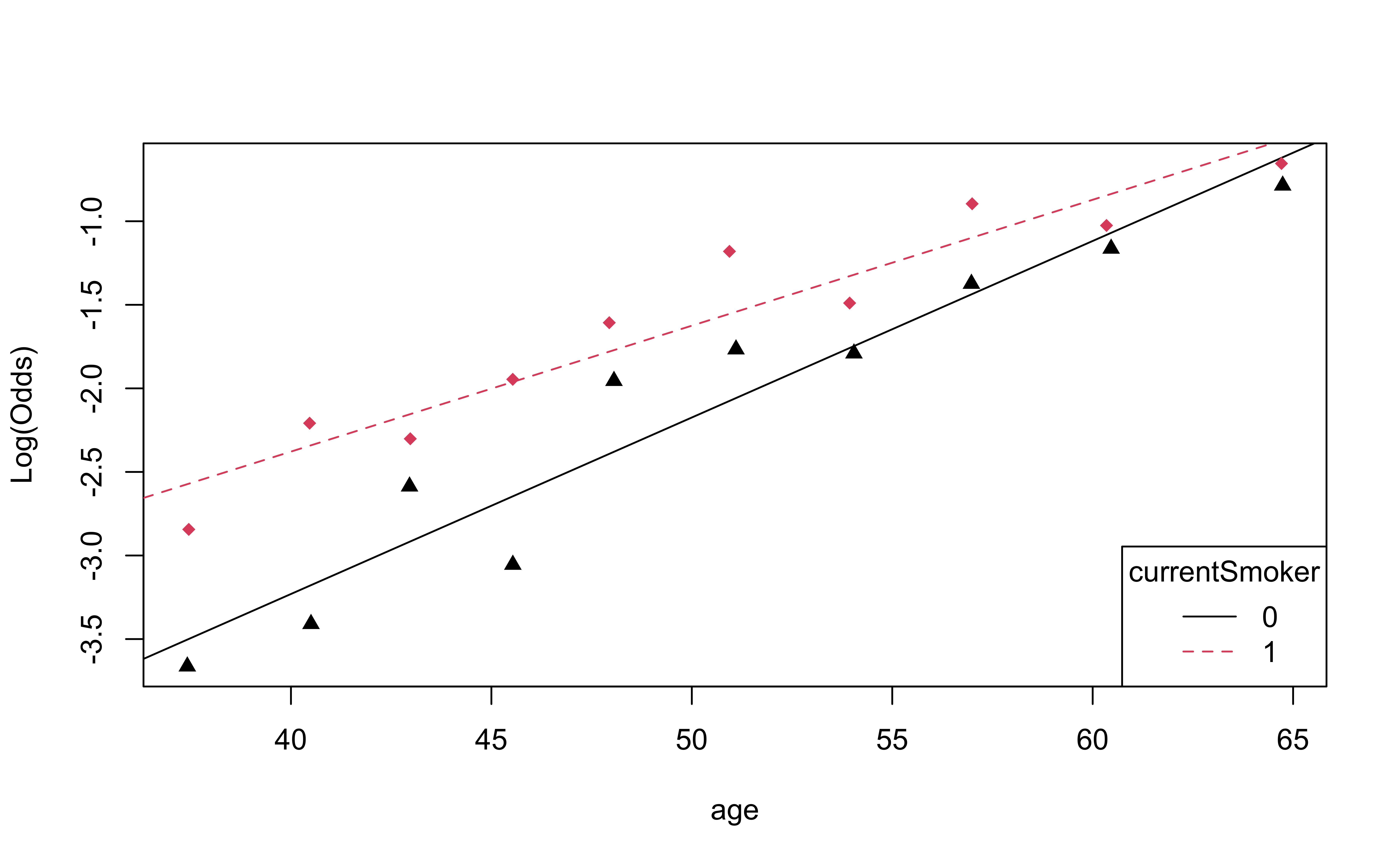
Checking linearity
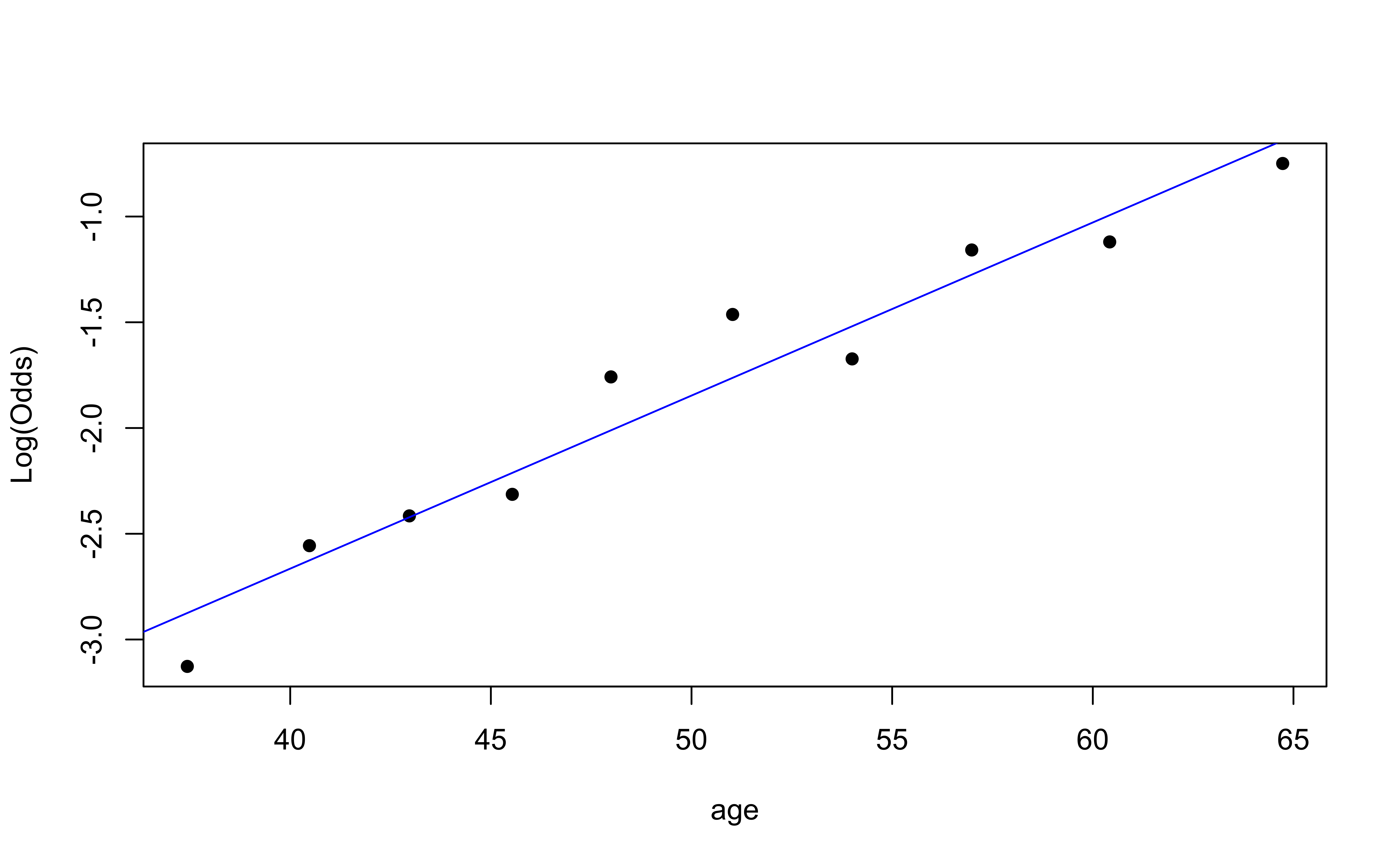
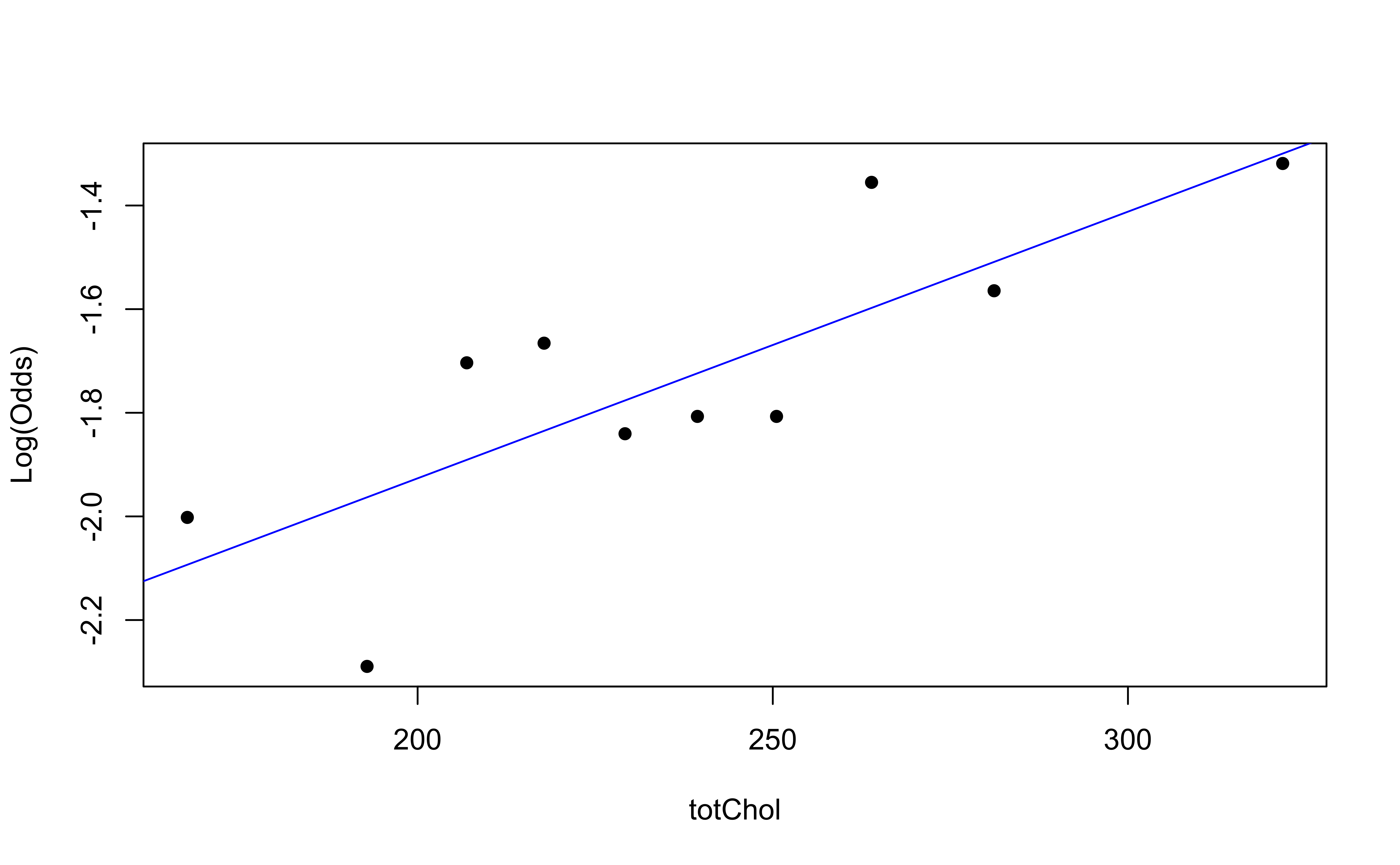
✅ The linearity condition is satisfied. There is a linear relationship between the empirical logit and the predictor variables.